הפוסט הבא הוא תחילה של סדרה שבה אתאר פעולות נפוצות ש- דאטה אנליסט מבצע ביומיום בעזרת שפת SQL. בפרק הנוכחי אתמקד באנליזות שאפשר לבצע בעזרת הוראת האגרגציה – Group by. (את הדוגמאות בפוסט כתבתי על מנוע של Postgre SQL).
לוג או רשימה של נתונים עם תאריך של ביצוע פעולה מסוימת מאפשר לנו לראות את המגמות (טרנדים) של הפעולות שבוצעו. כדי לחשב את המגמה בעזרת שפת SQL יש לקבץ את הנתונים לפי התאריך ולחשב את המטריקות שיעניינו אותנו.
חשוב לשים לב לרמת האגרגציה שלפיה רוצים לבנות את המגמה. האם רוצים לעבוד לפי רמת אגרגציה של יום, חודש, שבוע או אולי שעה.
דוגמה
להלן טבלת Orders שעליה נרצה לחשב טרנד ברמה היומית.
השאילתה תהיה
select
order_time_stamp::date,
count(order_id) as order_count,
avg(sum_order) as orders_avg,
avg(casewhen country='United Kingdom'then sum_order end) as orders_avg_UK,
avg(casewhen country='France'then sum_order end) as orders_avg_France
from
orders
groupby
1
orderby
1
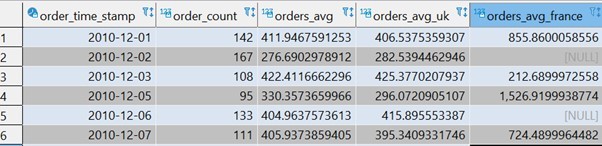
התוצאה שנקבל
הערות:
השדה order_time_stamp הינו שדה ברמת שעה ולכן המרתי את השדה מסוג שעה לסוג תאריך בעזרת אופרטור ::date
בדוגמה הזאת חישבתי מספר מטריקות, אך אפשר להוסיף כמה מטריקות שרוצים.
השטחה של טבלה
בטבלאות גרנולריות, כלומר טבלאות בהן הנתונים מגיעים מהמערכות השונות באופן לא מקובץ (כמו לוג של פעולות) יהיה לנו קל יותר לעבוד באופן מקובץ לפני שנוכל לבצע עליהן אנליזות. פעולה זאת מכונה לעיתים השטחה של טבלה.
למשל, הטבלה Item orders מכילה את כל הפריטים שנרכשו בכל ההזמנות בחנות E-commerce, ובכדי שנוכל לנתח את ההזמנות בקלות נצטרך לבצע השטחה לרמה של הזמנות. בהשטחה נעשה את פעולות האגרגציה לפי מספר הזמנה (לפי InvoiceNo) ונחשב את השדות שאנחנו רוצים על כל הזמנה.
בנוסף על כך, יצירת הטבלה המשוטחת מאפשרת גם לסדר את השמות של השדות ולנקות את הדאטה מתקלות.
בשביל ההשטחה נריץ את השאילתה הבאה:
select
InvoiceNo as order_id,
customerid,
country,
sum(UnitPrice*Quantity) as sum_order,
count(StockCode) as item_orders,
min(date(InvoiceDate)) as order_date,
avg(UnitPrice) as avg_unit_price
from
e_commerce.items_order
where
InvoiceDate<>'12/1/2010 8:26'
groupby 1,2,3
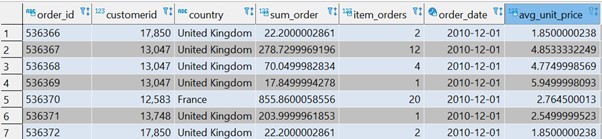
התוצאה:
הסבר
בשאילתה הנ"ל יצרתי אגרגציה לרמת הזמנות וכדי להוסיף מידע על ההזמנות הוספתי עוד רמות קיבוץ (customer_id,country). יכולתי להוסיף את השדות האלה לאגרגציה שלכל הזמנה יש מספר לקוח אחד ומדינה אחת.
לאחר שקבעתי את השדות לפיהן אני אבצע את האגרגציה, יצרתי מטריקות מעניינות שלפיהן ארצה לנתח אח"כ את טבלת ההזמנות.
הערות
בהוראת ה-where סיננתי שעה בעייתית שבה הייתה תקלה הנתונים.
את הטבלה המושטחת אפשר ליצור בתוך תת שאילתה, אבל מומלץ יותר ליצור טבלה חדשה או view כדי להקל עלינו להיעזר בה בשאילתות נוספות.
איתור ערכים כפולים
לפעמים דאטה אנליסט צריך לאתר ערכים כפולים בדאטה. בפעולה זאת משתמשים פעמים רבות כדי לבדוק האם יש לקוח שרכש יותר מפעם אחת או לפני חיבור בין טבלאות כדי לוודא שהמפתח הוא חד ערכי.
בטבלת ה- Orders שהזכרנו בסעיף הקודם יש שדה בשם customer_id שמתייחס למספר לקוח. והשאילתה הבאה תעזור לנו לבדוק האם לקוח הזמין יותר מפעם אחת.
select
count(customer_id) as cnt,
count(distinct customer_id) as cnt_d
from orders
תוצאה:
בשאילתה אני סופר את כמות הלקוחות שיש בשורות הטבלה ואת כמות הלקוחות היחודיים בטבלה. אם כמות הלקוחות היחודיים קטנה מכמות הלקוחות בטבלה אזי שיש לקוחות שהזמינו יותר מפעם אחת. אם המספר היה שווה זה אומר שכל לקוח הזמין פעם אחת בלבד.
כדי לראות את הלקוחות עצמם שהזמינו יותר מפעם אחת, נריץ את השאילתה הבאה:
select
customer_id,
count(order_id) as number_of_orders
from
orders
groupby
customer_id
having
count(order_id)>1
orderby
number_of_orders desc
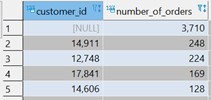
הסבר
בשאילתה ספרתי את מספר ההזמנות שכל לקוח עושה וסיננתי את הלקוחות שהזמינו רק פעם אחת כדי לאתר את הלקוחות הכפולים. את המיון ביצעתי כדי לראות בשורות הראשונות את הלקוחות שהזמינו הכי הרבה.
בתשובה לשאילתה אנחנו יכולים לראות שלקוח מספר 14911 הזמין 248 פעמים ולקוח מספר 12748 הזמין 224 פעמים.
השורה הראשונה אומרת שהיו 3,710 הזמנות שלהן לא היה מספר לקוח. מקרה זה מצביע על תקלה שיש בטבלאות כי לא יתכן הזמנות ללא מספר לקוח.
למדריך בסיסי בשפת SQL לחצו כאן. לתרגול SQL לחצו כאן.
להערות ורעיונות נוספים לנושאים שיהיו בסדרה מוזמנים לפנות אלי למייל: [email protected]
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept All”, you consent to the use of ALL the cookies. However, you may visit "Cookie Settings" to provide a controlled consent.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.