
This post is the beginning of a series in which I will describe common analytical SQL queries that a data analyst is doing on a daily basis. In this chapter I will focus on analyzes that can be done with the help of the aggregation instruction – Group by.
(I wrote the examples in the post on a PostgreSQL engine).
Analyzing trends with the help of Group by
Log or a list of data with a date of execution of an action allows us to see the trends of the actions. To calculate the trend using the SQL language, we must group the data by date and calculate the metrics that will interest us.
It is important to pay attention to the level of aggregation by which we want to build the trend. You can choose to work at the aggregation level of day, month, week or maybe an hour.
An example:
This is the Orders table on which we would like to calculate a trend at the daily level.

To get the trend by date the query should be:
select
order_time_stamp::date,
count(order_id) as order_count,
avg(sum_order) as orders_avg,
avg(case when country=‘United Kingdom’ then sum_order end) as orders_avg_UK,
avg(case when country=‘France’ then sum_order end) as orders_avg_France
from
orders
group by
1
order by
1
The result:
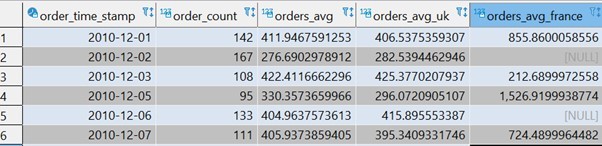
remarks:
- The order_time_stamp field is an hour-level field so I converted it to date-type level using operator “::date”
- In this example I calculated a small number of metrics, but may add metrics as much as you like.
Flattening tables
Many tables that originate from production are coming in granular forms and to analyse them more easily we will need to group them into what is usually called a Flatten table.
For example, the Item orders table that we saw in the last section contains all the items purchased in all orders in the e-commerce store. In order for us to analyze the orders easily we will need to flatten the table to orders level. In flattening we will group the table by order number (according to InvoiceNo) and calculate the fields we want for each order.
In addition, creating the flattened table also gives us the opportunity to arrange the names of the fields and clear the data of glitches.

For flattening we will run the following query:
select
InvoiceNo as order_id,
customerid,
country,
sum(UnitPrice*Quantity) as sum_order,
count(StockCode) as item_orders,
min(date(InvoiceDate)) as order_date,
avg(UnitPrice) as avg_unit_price
from
e_commerce.items_order
group by
1,2,3
Result:
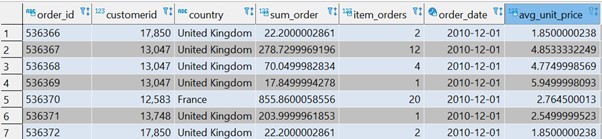
explanation:
The above query created an aggregative table at the level of orders. In order to add information about the orders I added more grouping fields (Customer_id, country). I could add these fields to ‘group by’ and was still able to keep aggregation at order level because any order has ‘one to one’ relations in those fields (any order could have only one ‘customerid’ or one ‘country’).
Notes: The flattened table can be created within a subquery, but it is better to create a new table or a view to make it easier for us to use it with additional queries.
Finding Duplicate Values
Sometimes a data analyst needs to identify duplicate values in the data. This is often used to check if a customer has purchased more than once or before joining tables to verify that the key is unique.
The Orders table we mentioned in the previous section has a field called customer_id that refers to a customer number. The following query will help us check if a customer has ordered more than once.
select
count(customer_id) as cnt,
count(distinct customer_id) as cnt_d
from
orders
Result:
Explain:
In the query I count the number of customers there are in the table and the number of unique customers in the table.
If the count of unique customers is less than the count of customers in the table then there are customers who have ordered more than once.
If the number was equal it means that each customer ordered only once.
To get the customers who have ordered more than once, we will run the following query:
select
customer_id,
count(order_id) as number_of_orders
from
orders
group by
customer_id
having
count(order_id)>1
order by
number_of_orders desc
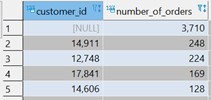
Explanation:
In the query I counted the number of orders each customer makes and filtered the customers who ordered only once to find the duplicate customers. I sort the table to get the first rows of the customers who ordered the most.
In result we can see that customer number 14911 ordered 248 times and customer number 12748 ordered 224 times.
The first line means that there were 3,710 orders of which there was no customer number. This case indicates a malfunction in the tables because it is not possible to place orders without a customer number.
This article was written by Yuval Marnin.
If you have a need to hire a freelancer data analyst you may contact me at: [email protected]
You may also hire me through upwork platform on that link:
https://www.upwork.com/freelancers/~018940225ce48244f0\
Further reading
The advantage of hiring a freelance data analyst.
What does a data analyst is doing and how it can help your company.

